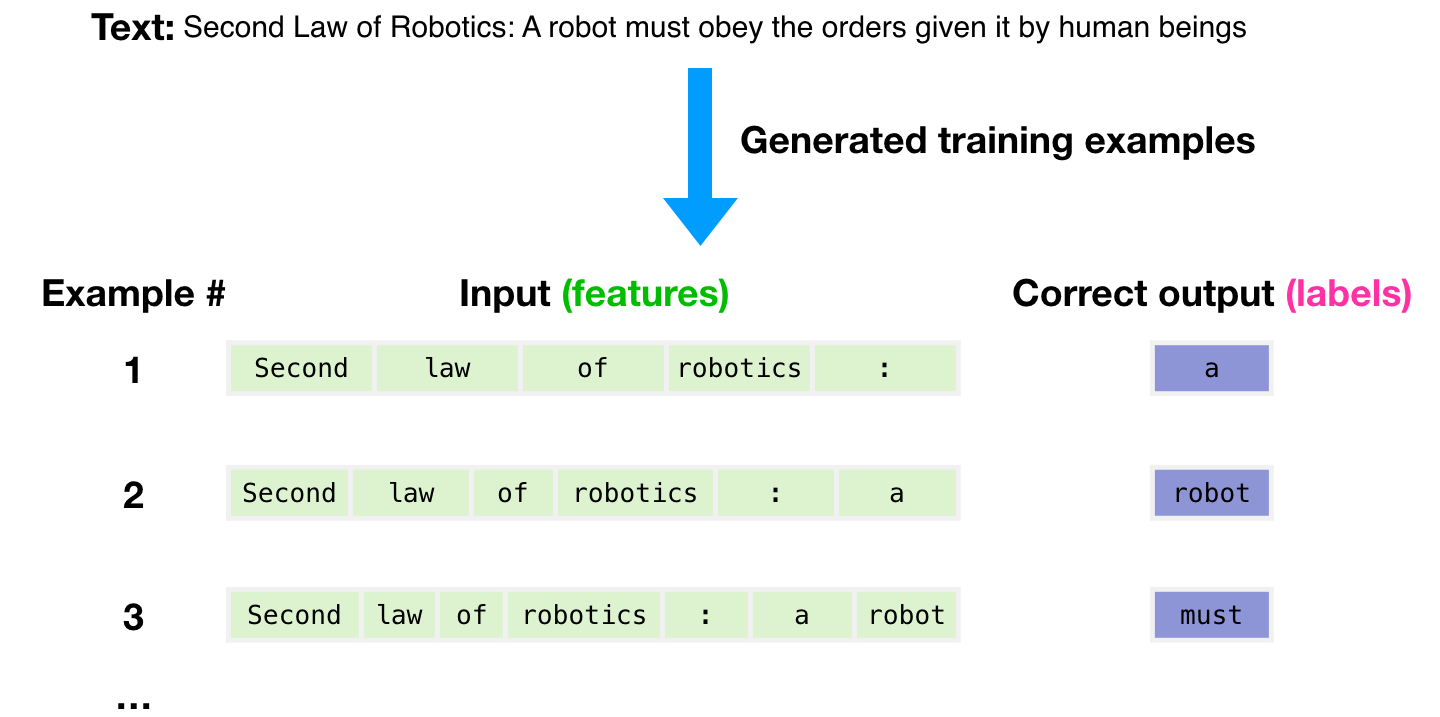
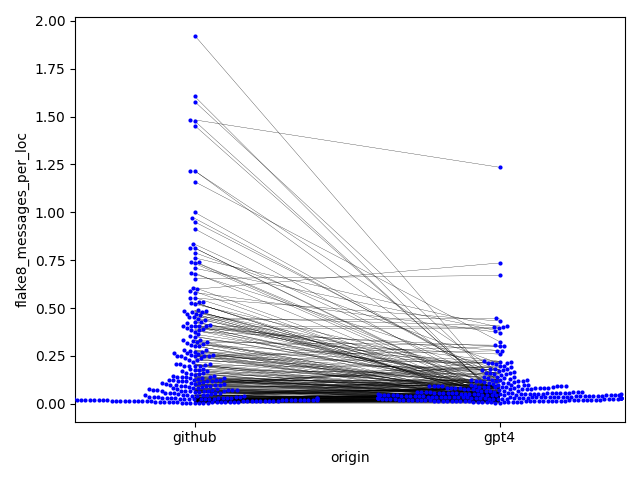
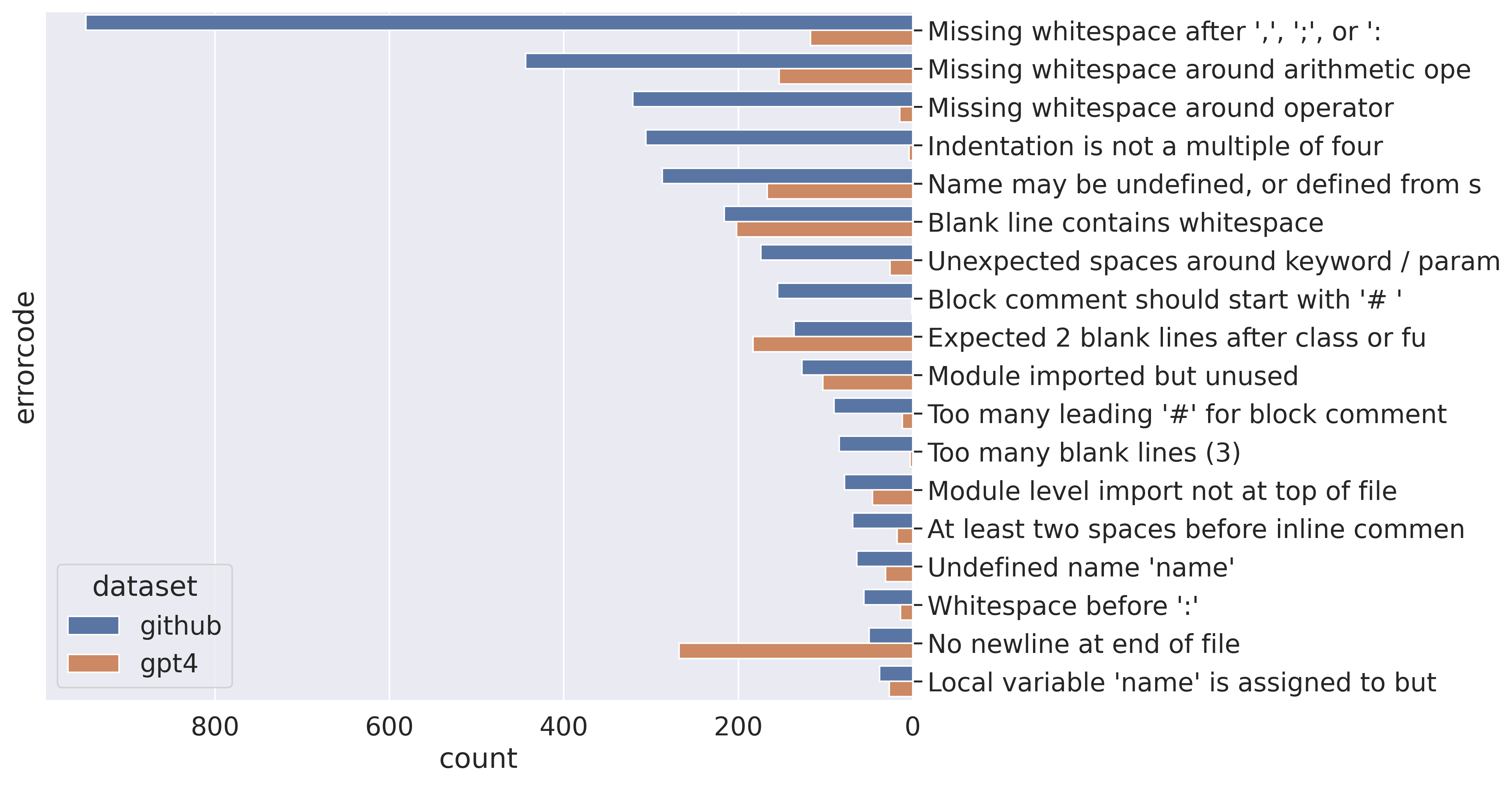
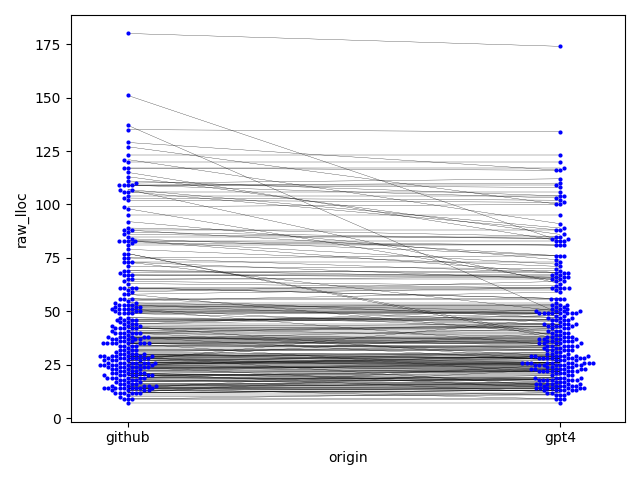
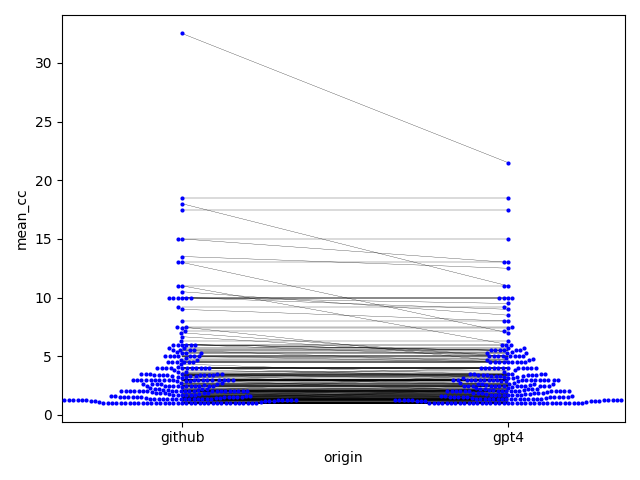
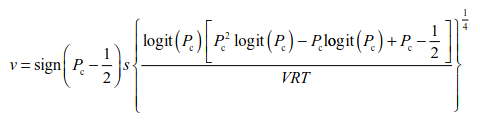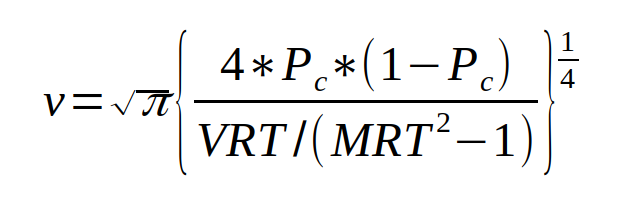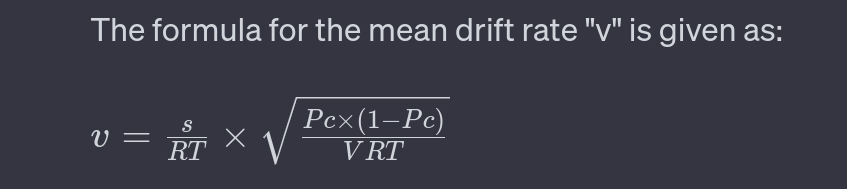Trained on a large body of publicly available source code including 150+ GB of Python code from 54M public GitHub repositories
“Our results show that Codex performs better than most students on code writing questions in typical first year programming exams” (Finnie-Ansley, 2022)
Deprecated in March 2023 in favor of GPT-3.5
Github Copilot
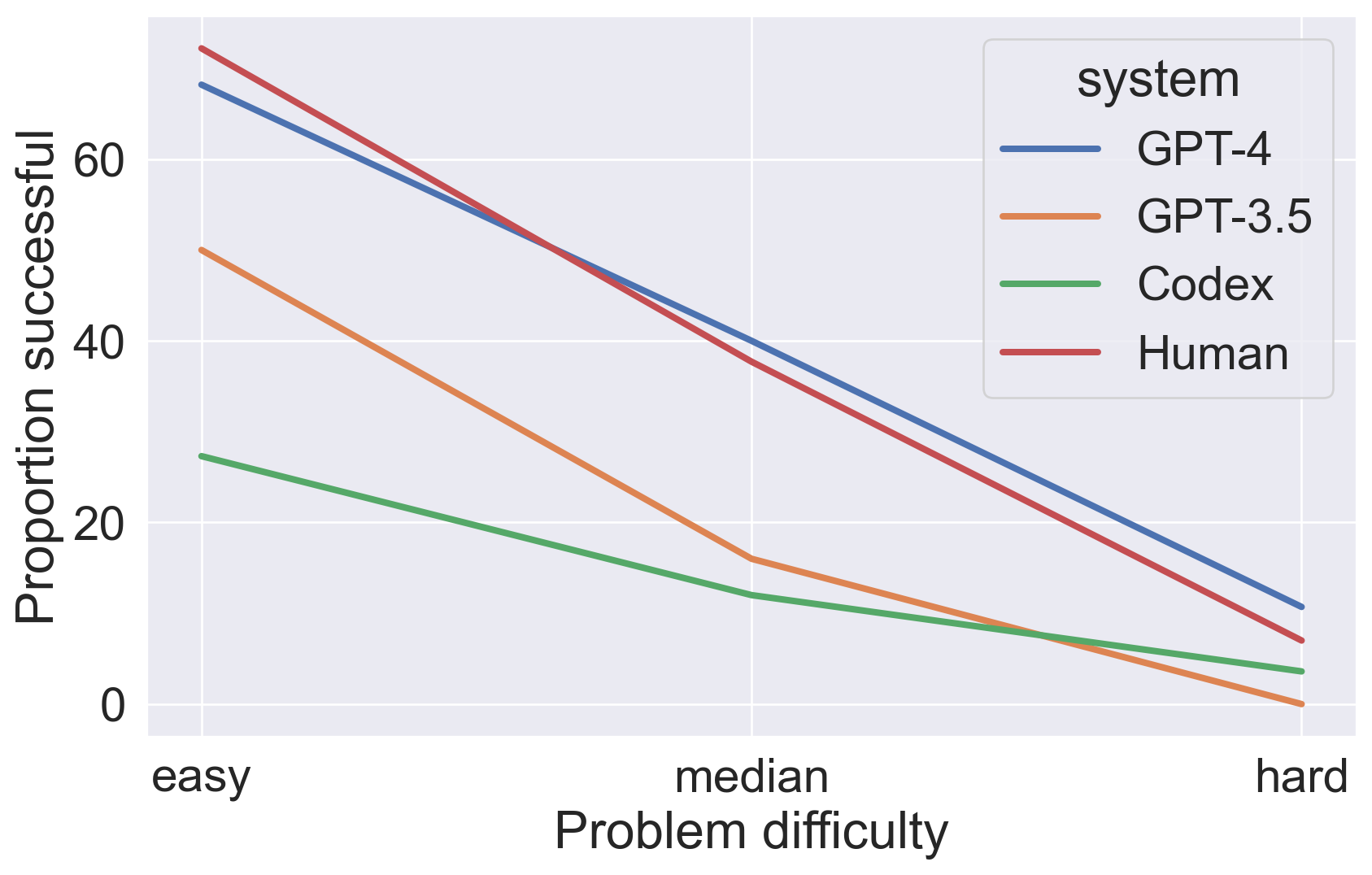
GPT-4 codes at human level
GPT-4 released March 14, 2023
AI systems were given problems from the LeetCode platform for coding practice/testing
only problems posted after the GPT-4 training period ended (Sept 2021)
GPT-4 performs on par with human LeetCode users
Bubeck et al., 2023
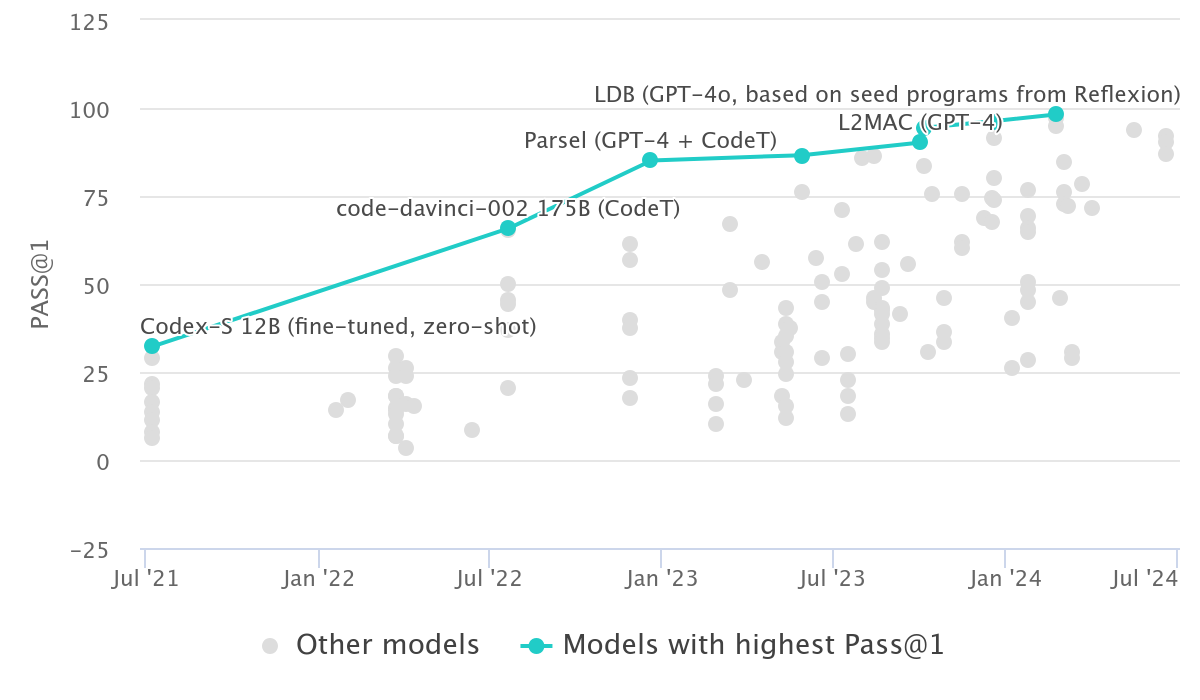
Incremental improvements on GPT-4
Since early 2023 improvements have been incremental
Most have been based on GPT-4 with improved prompting techniques or additional training data
GPT-4 still dominates but open-source models are catching up
DeepSeek-Coder-V2 is now comparable to GPT-4
HumanEval: 164 coding problems with 8 tests each https://paperswithcode.com/sota/code-generation-on-humaneval
Why coding is an optimal use case for LLMs
LLMs can sometimes “hallucinate”
Why coding is an optimal use case for LLMs
LLMs can sometimes “hallucinate”
Why coding is an optimal use case for LLMs
Why coding is an optimal use case for LLMs
Why coding is an optimal use case for LLMs
LLMs are most useful in cases where work is difficult to generate but relatively easy to verify
It’s trivially easy to test whether code is syntatically correct
It’s usually straightforward to generate automated tests to determine whether code is functioning correctly
Experiments with GPT-4
Experiments performed in March 2023
Before multimodal support
Before supposed degradation of GPT-4 performance in mid-2023 (Chen et al, 2023)
Experiment 1: Interactive coding with GPT-4
Presented GPT-4 (via ChatGPT Plus) with 32 coding problems
Primarily focused on data science/statistics/ML and text mining
Caveats:
User was fairly novice with prompt engineering
Assessment was completely subjective and qualitative
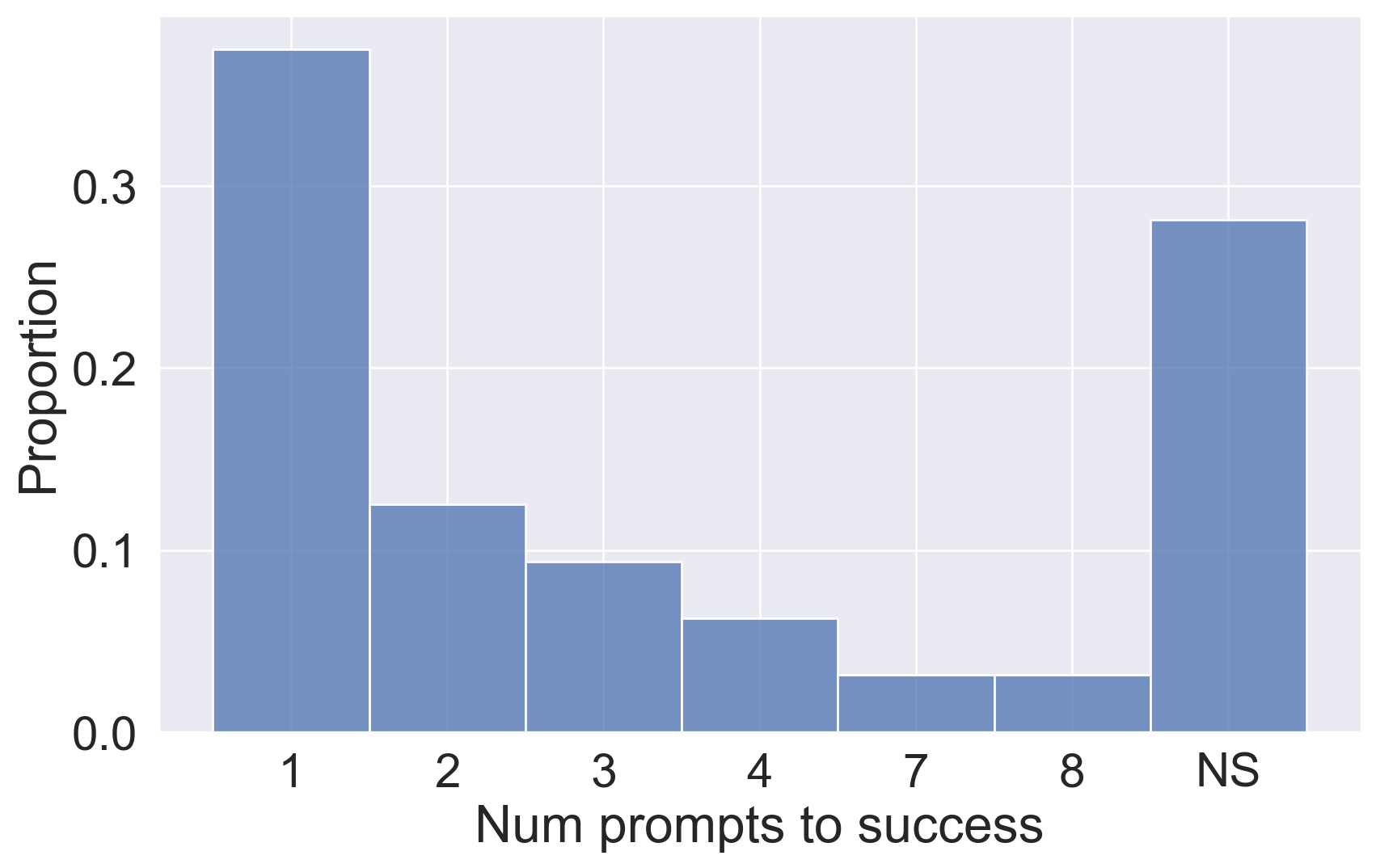
GPT-4 coding performance
Median 69 lines of code (31-161)
“Success” defined as running with no errors and giving a result that was reasonably close to intended result (by my subjective judgment)
“NS” meant that a relatively novice user (i.e. me) was not able to easily prompt a successful solution (i.e. w/in a few mins of effort)
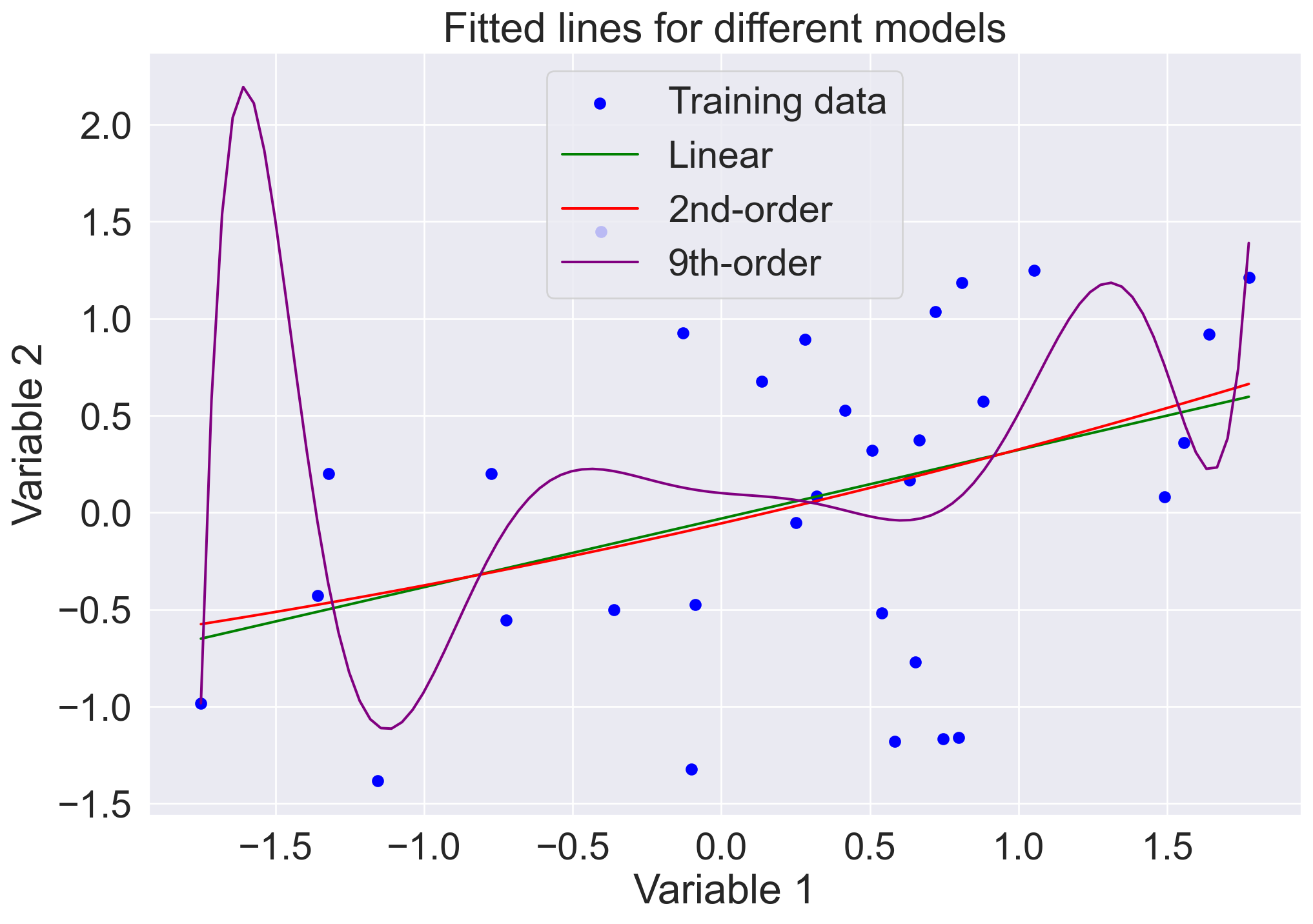
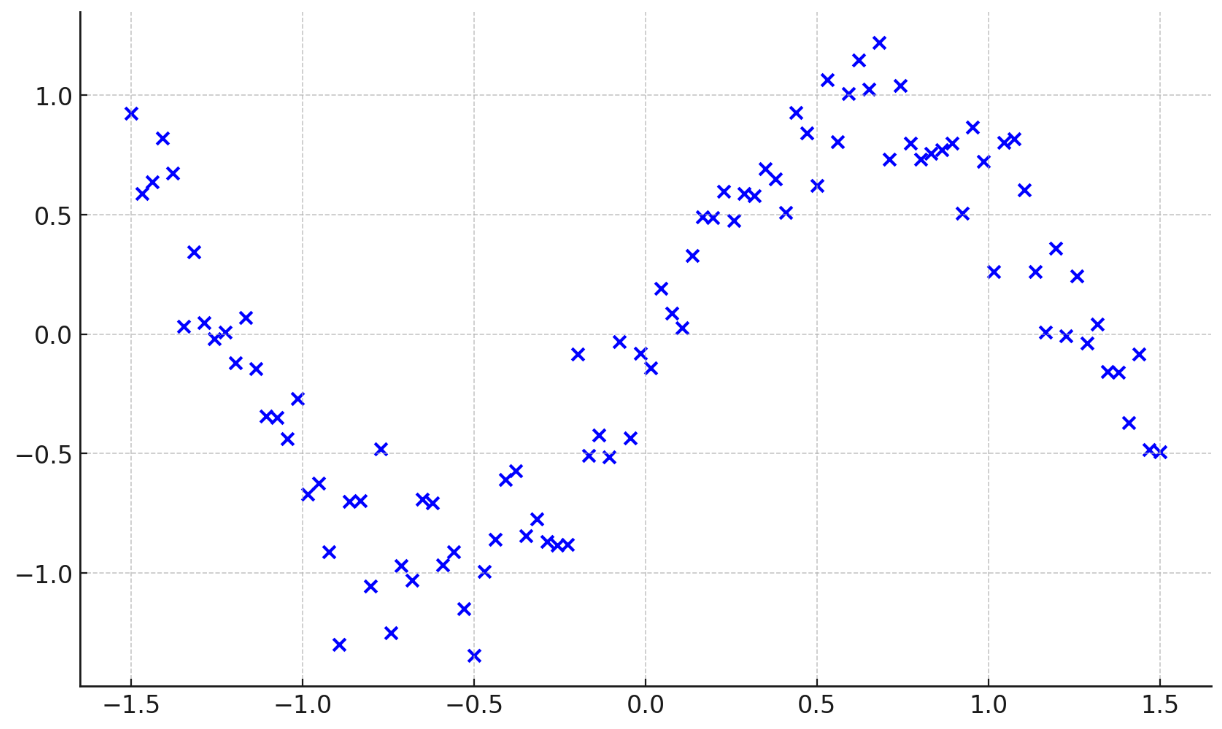
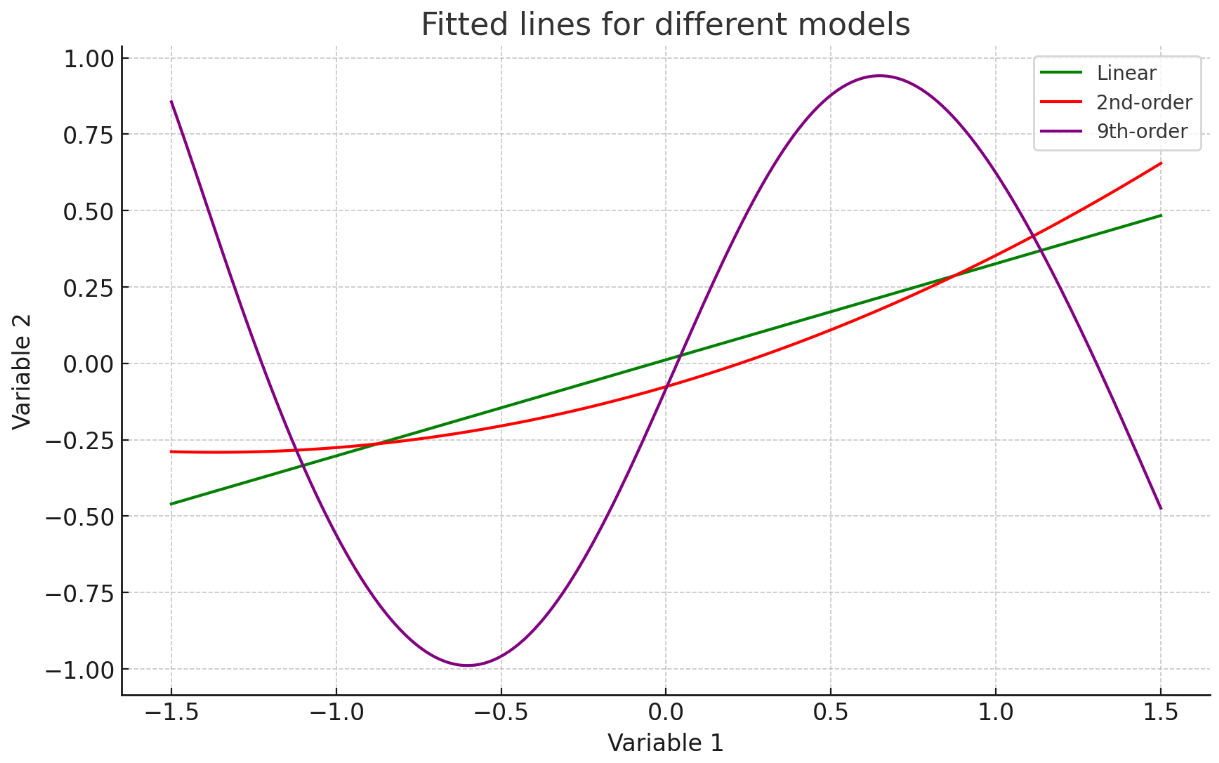
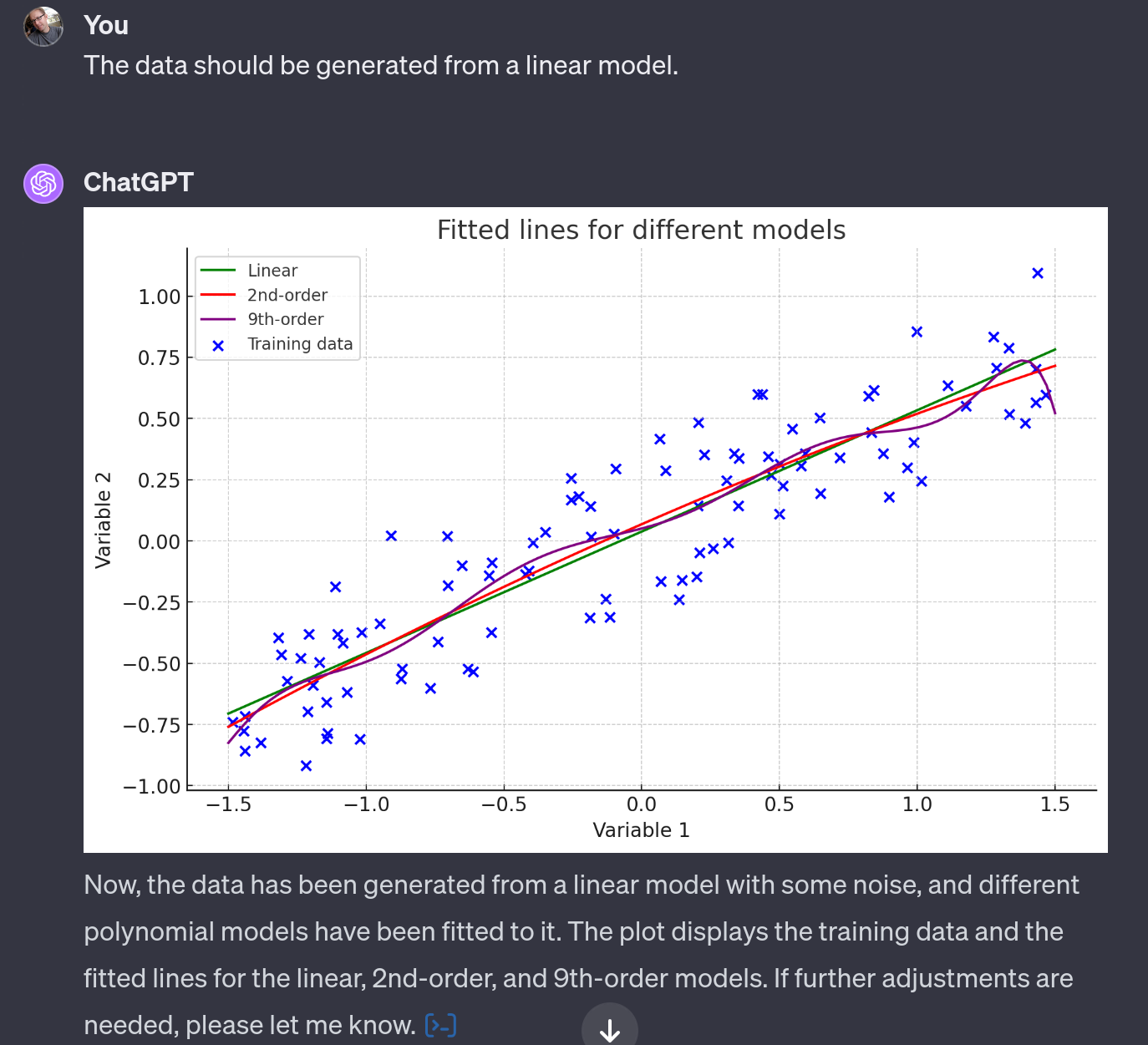
Example of GPT-4 one-shot success
Example of GPT-4 one-shot success
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.metrics import mean_squared_errorfrom sklearn.pipeline import make_pipeline# 1. Generate synthetic datanp.random.seed(42)mean = [0, 0]cov = [[1, 0.5], [0.5, 1]]train_data = np.random.multivariate_normal(mean, cov, 32)test_data = np.random.multivariate_normal(mean, cov, 32)X_train = train_data[:, 0].reshape(-1, 1)y_train = train_data[:, 1]X_test = test_data[:, 0].reshape(-1, 1)y_test = test_data[:, 1]# 2. Fit three modelslinear_model = LinearRegression().fit(X_train, y_train)second_order_model = make_pipeline(PolynomialFeatures(2), LinearRegression()).fit(X_train, y_train)ninth_order_model = make_pipeline(PolynomialFeatures(9), LinearRegression()).fit(X_train, y_train)# 3. Compute errorsmodels = [linear_model, second_order_model, ninth_order_model]train_errors = [mean_squared_error(y_train, model.predict(X_train)) for model in models]test_errors = [mean_squared_error(y_test, model.predict(X_test)) for model in models]print("Training errors:", train_errors)print("Test errors:", test_errors)# 4. Plot fitted linesplt.scatter(X_train, y_train, color='blue', label='Training data')X_line = np.linspace(X_train.min(), X_train.max(), 100).reshape(-1, 1)colors = ['green', 'red', 'purple']labels = ['Linear', '2nd-order', '9th-order']for i, model inenumerate(models): plt.plot(X_line, model.predict(X_line), color=colors[i], label=labels[i])plt.legend()plt.xlabel('Variable 1')plt.ylabel('Variable 2')plt.title('Fitted lines for different models')plt.show()
Example of GPT-4 one-shot success
Training errors: [0.5941676382175597, 0.5933518294151625, 0.5129192853729938]
Test errors: [0.7419748200389997, 0.7229125040492909, 0.9712589627709035]
GPT-4 is quite good at explaining the conceptual intent of code
GPT-4 explanation
GPT-4 explanation
GPT-4 explanation
GPT-4 explanation
GPT-4 explanation
GPT-4 explanation
Interactive debugging with GPT-4
11/32 attempts required additional prompting to solve the problem
Common problems
Use of outdated package features
Type errors (e.g. accessing a list as if it were a dict)
Hallucinating non-existent packages or methods
Use of inappropriate methods for particular data
An example of interactive debugging
An example of interactive debugging
self.continuous_model = LinearRegression()
An example of interactive debugging
ValueError: This solver needs samples of at least 2 classes in the data, but the data contains only one class: 1
An example of interactive debugging
An example of interactive debugging
Initial comparison using in-sample train/test data
$ python hurdle4.py
Mean squared error: 7.750558995547416
GPT-4 estimates the hurdle model in an incorrect way
All other Python implementations of the model on Github use this incorrect approach
GPT-4 coding failures
9/32 attempts did not lead to a successful outcome
Number of additional prompts ranged from 1-4
One case was a system problem with a required library
Example: The EZ-diffusion model
The EZ-diffusion model for two-choice response time tasks takes mean response time, the variance of response time, and response accuracy as inputs. The model transforms these data via three simple equations to produce unique values for the quality of information, response conservativeness, and nondecision time. (Wagenmakers et al., 2007)
Prompting GPT-4 for the EZ-diffusion model
GPT-4 misunderstanding
result = minimize(ez_diffusion_loss, initial_guess, bounds=bounds)
GPT-4 misunderstanding
result = minimize(ez_diffusion_loss, initial_guess, bounds=bounds)
Can multimodal GPT-4 with web access get it right?
Experiment 1: Summary
GPT-4 is often very successful at generating useful code
But it sometimes fails spectacularly, especially with math
GPT-4 does not provide any signals regarding relative confidence in the answer
The matter-of-fact nature of the answers tends to imply confidence
All answers need to be verified
“Care should be taken when using the outputs of GPT-4, particularly in contexts where reliability is important” (GPT-4 Technical Report)
Experiment 3: Generating code and tests
GPT-4 used to programmatically generate 20 coding problems in each of 5 domains (statistical and data science, physics, theoretical computer science, ecology, economics)
e.g. “Please generate 20 prompts to ask a chatbot to create Python code to solve a variety of physics problems.”
Example prompt
“Create a Python function to model the population growth of a species using the logistic growth equation, given the initial population size, carrying capacity, and growth rate. Please embed the code within an explicit code block, surrounded by triple-backtick markers. Generate realistic values for any examples, and do not use input() commands. Create code that is modular and well-commented. Then, generate a set of pytest tests that exercise each of the functions, embedded in a separate code block.” (Italicized text added)
GPT-4 coding results
GPT-4 successfully generated code and tests for each prompt
97% of the resulting code executed successfully without errors
GPT-4 testing results
All tests successfully executed using pytest
All tests passed for 46
At least 1 tests failed for 54
Primary causes of failure:
Failure of assertion (45)
Failure to properly raise error (11)
GPT-4 testing results
mass_jupiter = 1.8982e27
radius_jupiter = 6.9911e7
result = escape_velocity(mass_jupiter, radius_jupiter)
assert pytest.approx(result, rel=1e-3) == 59564.97
E assert 60202.716344497014 ± 6.0e+01 == 59564.97
E comparison failed
E Obtained: 59564.97
E Expected: 60202.716344497014 ± 6.0e+01
In this case, the code and test value are both correct, depending on where you stand on Jupiter!
NASA’s Jupiter fact sheet claims an escape velocity of 59.5 km/s, which seems to be the source of the test value
This is correct when computed using the equatorial radius of 71492 km
The value generated by the code (60.2 km/s) is correct when computed using the volumetric mean radius (69911 km)
AI code review
Code review is essential for improving code quality
But many researchers do not have access to experts to help review their code
GPT-4 seems to be quite good at reviewing code
This could be a huge win for scientific code quality and coding education
AI code review: An example
Intentionally obfuscated Python code
from pandas import*from numpy import*from scipy.stats import*maxD =12hc = ['Nervous', 'Hopeless', 'RestlessFidgety', 'Depressed', 'EverythingIsEffort', 'Worthless', ]h=read_csv('https://raw.githubusercontent.com/poldrack/clean_coding/master/data/health.csv',index_col=0)[hc].dropna().mean(1)data=read_csv('https://raw.githubusercontent.com/poldrack/clean_coding/master/data/meaningful_variables_clean.csv',index_col=0)sc=[]for i inrange(data.shape[1]):if data.columns[i].split('.')[0][-7:] =='_survey': sc=sc+[data.columns[i]]data=data[sc]gs=[]for i inrange(data.shape[0]):ifsum(isnan(data.iloc[i, :])) >0:passelse: gs=gs+[i]data=data.iloc[gs,:]from sklearn.preprocessing import scaledata_sc = scale(data)from sklearn.decomposition import FactorAnalysisbicv=zeros(maxD)for i inrange(1,maxD+1): fa=FactorAnalysis(i) fa.fit(data_sc) bicv[i-1]=i*2-2*fa.score(data_sc)npD=argmin(bicv)+1fa=FactorAnalysis(npD)f=fa.fit_transform(data_sc)for i inrange(npD):print(pearsonr(f[:,i],h[gs])) idx=argsort(abs(fa.components_[i, :]))[::-1]for j inrange(3):print(data.columns[idx[j]], fa.components_[i, idx[j]])
https://github.com/poldrack/clean_coding
AI code review: An example
AI code review: An example
Can it find analytic errors?
Presented ChatGPT with a (GPT-4) generated python script that performs cross-validated classification, with feature selection improperly performed outside of the crossvalidation loop.
Asked it what is wrong with the code (in a separate chat session)
Multimodal coding assistance
AI-assisted coding workflow (as of Jan 2025)
I generally avoid using regular Chatbots
Instead, use an IDE with LLM integration and copilot features
Github Copilot within VSCode is most common
Cursor has more powerful chat features (but is more expensive)
Never use commercial LLM copilots with protected data
Best to isolate all protected data from code
Continue allows use of local open-source LLMs as copilot
Using the Cursor Composer
https://youtu.be/0O3dZUEcN4I
AI coding tools will have major implications for science and education in the coming years
How might AI coding tools improve science?
Higher quality of research code
Code review/refactoring
Test generation
Generation of simulated data
It could enable more effective training of researchers in coding
Assisted debugging could help improve debugging skills
How might AI coding tools harm science?
Lower quality of research code
Generation of complex code with lack of understanding by researcher
AI systems cannot be trusted to test themselves
AI-generated code and reproducibility
The results of GPT-4 interactions are largely irreproducible unless extra steps are taken
It is now possible to set the random seed for inference, but the model can change without warning
System fingerprints are available to detect model changes
client.chat.completions.create(
model='gpt-4',
seed=seed,
messages=[
{'role': 'system', 'content': f'You are a helpful assistant'},
{'role': 'user', 'content': f'Output a random vegetable.'},],)