Code Sharing¶
Prerequisites¶
The steps to getting started below assume some basic skills, which are presented in more detail in the Basic Skills section of the guide:
Using the command line shell
Understanding file systems
Understanding version control using git
In addition, see the section on Reproducible Analysis for suggestions on how to write and organize your code and data in a way that enhances reproducibility.
Getting started with code sharing¶
Step 1: Set up git and Github¶
Git is currently the most popular version control system, and it allows one to easily share code via github.com, which is the most popular online git repository system.
Install git on your local computer: https://git-scm.com/downloads
Create an account on Github: https://github.com/
It will make your life much easier if you set up an SSH key for your local computer and add it to your Github account: This way, you won’t need to enter your github password every time you push code to the repository. See this article for more.
Step 2: Choose a license for your code¶
Specifying a license for your code allows you to stipulate how others can re-use the code. In general, you should select the most permissive license possible — that is, the license that gives the greatest possible freedom for others to reuse the code.
MIT License is a good default choice as it allows people to do almost anything with your code, which will maximize its potential reuse
If you are going to be collaborating with an existing code base, then it’s best to select the license that they are already using
If you need help determining which license is most appropriate for your particular situation, see https://choosealicense.com/
Preventing commercial reuse might sound like a good idea, but in most cases it’s not: https://freedomdefined.org/Licenses/NC
Step 3: Create a new repository on Github, and clone it to your computers¶
Create a new repository from your Github page (using the menu at the top right with the + sign)
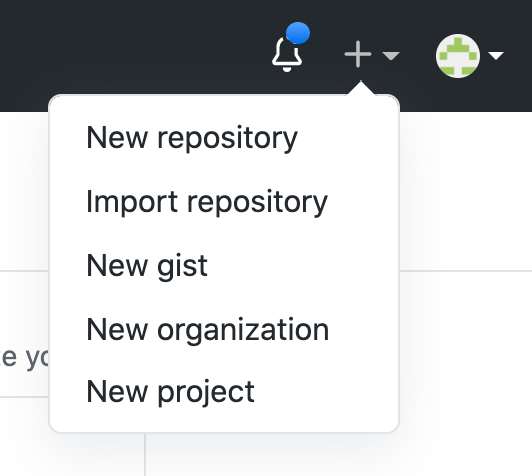
Complete the form to create the new repo, including selecting your license and creating a README file
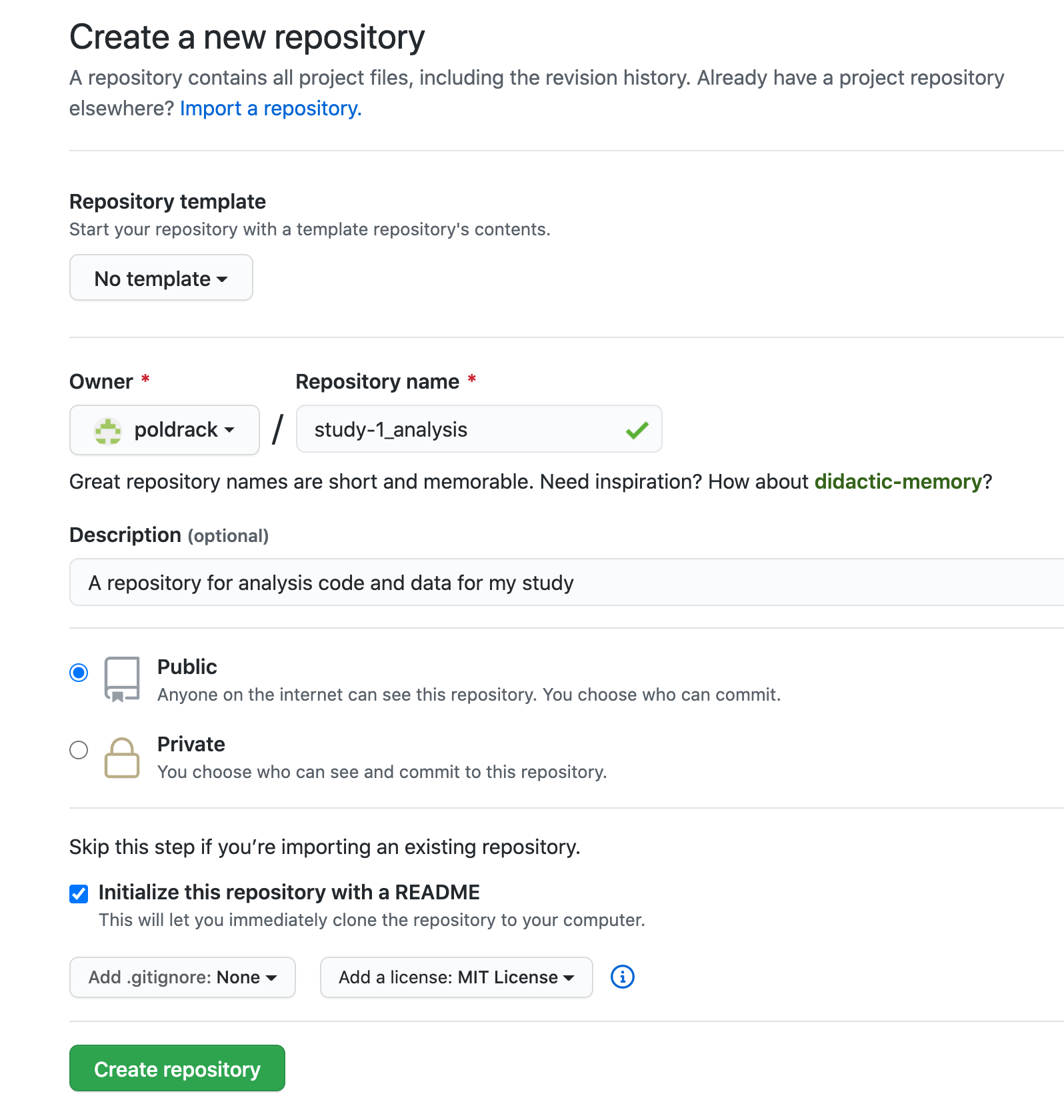
Once you create the repository, you will be taken to the main page for the repository. Obtain the link to your repository under the Code tab, and copy it.
On your local computer, clone the github repository using:
git clone \<link copied from github page\>This will create a new directory on your computer with the same name as your github project.
Note: Some editors, such as RStudio and Visual Studio Code, allow one to directly connect to github within the editor; see below for more details.
Step 4: Organize your code¶
The main goal of organizing your code is to make it clear to you and to others where to find the different parts of your project. See the additional guidance in the section on Reproducible Analysis for how to write code that is clear and readable.
Regardless of the particular scheme that you use to organize and name your files, you should use the same scheme for all of your projects. This will make it easier for you to find things and remember what you’ve done in the future. Different languages have different conventions about how to structure the code; the most important thing is that you follow common conventions when they exist, and that you are consistent in your own work.
Some researchers include data within their code directory; see the section on Data Sharing for more on the issue of how to organize and share data.
For example, if you were creating a new project called study-1 and decided to include the data in the same directory as the code, you might structure the directory as follows, following to the Psych-DS and Project Tier frameworks:
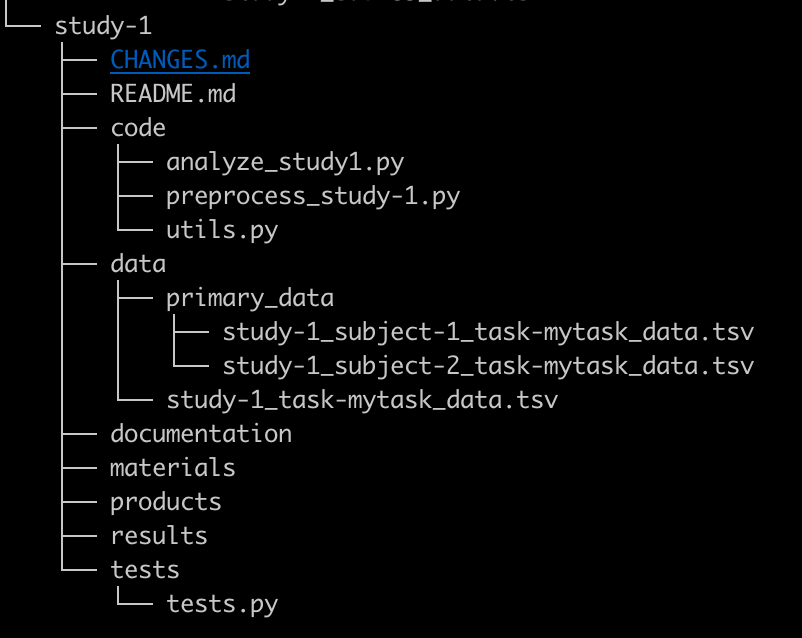
Step 5: Commit your code to the local repository¶
As you write your code, commit it to the repository. First, you need to add it to the staging area:
git add \<filename\>
Then you commit it, providing a message that describes the changes you have made.
git commit -m ”\<a message describing the commit\>”
You should commit your code regularly. For example, any time you add a new function or a new section to your code, you should commit. The commit history allows you to look back and see what you have done, and also allows you to reverse changes that you have made.
Step 6: Push your changes to Github¶
To push your changes back to the repository on Github, use the following command:
git push origin master
This tells git to push the changes that you have committed to the repository on github (which by default is labeled as origin), into the branch called master (don’t worry about branches just yet).
Step 7: Push your code to the repository¶
You will first need to pull the files that were created when the repository was created, such as the License file:
git pull origin master
You can then push your files to the remote repository:
git push origin master
When you are ready to publish your work:¶
Step 1: Create a release¶
When you are ready to save a fixed version of the code (for example, when you submit a paper), you can create a release. See the github guide to creating a release for instructions on how to do this.
Step 2: Create a citable identifier for your release¶
In order to make your code citable, it is useful to have a digital object identifier (DOI) for your code. You can create these easily by linking your github repository to Zenodo.org. Then, any time a release is created on github, it will be deposited to Zenodo and a new DOI will be created. See the github guide to citeable code for instructions on how to set this up. This has the benefit of allowing one to cite a specific version of the code used at a particular point in the project (e.g. upon submission of the manuscript), which enhances reproducibility.
Frequently Asked Questions¶
What is a “repository”?¶
By “repository” we mean a folder that is dedicated to a specific project, containing both the data and code for that project, which is under version control (e.g. using git).
It’s generally best practice to place all of these within a folder on your filesystem, so that they can be separated out from other kinds of documents and you can easily find them (such as “Dropbox/code”).
It’s also a good idea to place them within a location that will be backed up by whatever cloud service you use (Dropbox, Google Drive, Box, etc), so you have an extra backup in addition to your remote code repository
What is a license, and how should I choose one for my project?¶
Software licenses describe the rights and responsibilities of users of your code from two perspectives: developers and end-users. An end-user is anybody who uses any software that includes your code. A developer is somebody who writes additional code, either by modifying your code or by including some portion of your code in a larger project.
The software license is generally stored in full in the base directory of the repository, either in a LICENSE or COPYING file.
Assuming you would like your code to be reused, you will likely prefer a free or open-source software license, any of which will grant broad permissions to copy, reuse and remix your code in the context of other projects. A useful resource for finding the right license for your code is ChooseALicense.com.
Apart from the specific terms of each license, the most significant thing to consider is license compatibility, or the ability to combine code released under different licenses. There are extensive discussions over licensing and what is the best license for sharing code, but in practice the license to choose is the common license among the community where your code fits best. For example, the MIT and Apache 2 licenses are very common in the Neuroimaging in Python (Nipy) community, making these pragmatic choices for neuroimaging tools written in Python. If you are writing code that fits into a community where the GPL is prevalent, the Free Software Foundation maintains a list of licenses and their compatibility.
Less common for software but increasingly common for textual content like documentation are the Creative Commons family of licenses. They also provide a tool for selecting a license.
Note that there is very little case law on open-source licenses. Licenses are mostly a statement of principles, and all of the baroque behavior around them, such as avoiding mixing “incompatible” licenses, has little to no legal basis.
Should I include a non-commercial limitation in my license?¶
Many open licenses include a non-commercial clause, such as that in the Creative Commons NonCommercial suite of licenses:
NonCommercial means not primarily intended for or directed towards commercial advantage or monetary compensation. For purposes of this Public License, the exchange of the Licensed Material for other material subject to Copyright and Similar Rights by digital file-sharing or similar means is NonCommercial provided there is no payment of monetary compensation in connection with the exchange.
The intent of such clauses is to prevent private companies from exploiting the labor of the author(s) as an alternative to hiring an author or purchasing the content. This in turn makes the prospect of contributing free labor to a project more appealing by making it less likely that the contributors’ work will be repurposed in this way.
It is, however, unclear whether a non-commercial license prevents a for-profit company from using the material in any capacity, or if the restriction applies to processes that lead to commercial activity, or more strictly as a component of a product to be sold. This ambiguity can lead to for-profit entities avoiding any software that might contain such a provision, to avoid legal exposure.
The use of these licenses can thus reduce the adoption of a particular tool within a significant segment of the scientific community, working against goals of standardization, and thus reproducibility.
What is a “branch” and how can I use them?¶
A branch is a chain of git commits, which represents the evolution of a repository. Each repository will have a canonical branch, usually called “master”. By looking at “master” at any given time, you can see the current state of the repository and the chain of commits that produced this state. Other branches may be used as an organizational tool by separating chains of commits according to particular tasks.
When developing, it is frequently useful to make commits before they are ready to be included in the “official history”. For example, when fixing a bug, a common pattern is to create a new branch, write a test that demonstrates the bug, and then fix the bug:
Retrieve the latest state of the repository from the server and create a branch based on the latest commit on master. The “origin” remote is used here, but if contributing to somebody else’s repository, consider using “upstream” (see the next section to set up upstream).
git fetch origingit switch -C fix-bugXYZ origin/master
Create a new test, and verify that the tests fail. This is a bit more free-form.
Commit the changes and push to the server. This announces to collaborators what you’re working on. If your server has continuous integration tests, it will simplify evaluation. This is also when to open a pull request (see next section). The -u flag ensures that future calls to git push/git pull will associate the local fix-bugXYZ branch and the remote origin/fix-bugXYZ:
git add path/to/testgit commit -m “TEST: Reproduce bug XYZ; tests fail”git push -u origin fix-bugXYZ
Resolve the bug, and verify that the tests pass.
Commit and push the changes. Since we used the -u flag above, we can simply use git push here:
git commit -m “FIX: Make ABC change to fix bug XYZ; tests pass”git push
Pushing to a remote branch allows collaborators to inspect the changes. If you’re using automatic testing on the remote, the test failure and resolution become easily verifiable prior to inclusion in the master branch.
The same principle applies for new features or other modifications. This is also useful for more exploratory changes that may never be included in the master branch, and makes explicit the process of resolving conflicts, if two developers are working on different components simultaneously.
What is a “pull request” and how can I use them to collaborate?¶
A pull request is a way to request that code from a particular branch or fork be integrated (“pulled”) into another branch. A common model for collaborative development would be as follows. Let’s say that one researcher (A) has developed a project called analysisXYZ, and another researcher (B) wants to add a new feature to that project. The steps would be:
Researcher B would create a fork of this project, which is basically a copy of the project that lives separately in Researcher B’s github account, and clone this fork onto their local computer.
In order to be able to keep the fork up to date with the original repository, Researcher B would create a new remote in their local version of the fork, usually called “upstream”:
git remote add upstream \<link to original repo\>
Researcher B would modify the code in their fork to add the new feature, commit the changes.
Prior to making any changes, the upstream remote should be fetched to ensure that changes are made to the latest state, reducing the chance for conflict:
git fetch upstream
Changes should almost always be made on a new branch, diverging from the master branch on the upstream remote. Working on the master branch is strongly discouraged. It is good practice to use a short but descriptive branch names, for example, fix-bugXYZ.
git switch -C fix-bugXYZ upstream/master
Researcher B pushes their changes back to the github repository of their fork (remote origin), specifying the branch (for example, fix-bugXYZ):
git push -u origin fix-bugXYZ
Researcher B goes to the github page for their fork, selects the pull requests tab, and creates a new pull request, which will encompass all of the changes that have been committed. The pull request description should be as detailed as possible.
Researcher A reviews the pull request, and makes suggestions for changes. Once they are satisfied with the request, they merge the request, which integrates the changes into the master branch on the original repo.
How can I push an existing repository on my computer to github?¶
Your github repository is treated as a remote repository by your local computer. When you clone a repository from github, the remote is automatically generated and given the name origin. Sometimes you might wish to add a remote for an existing repository on your computer, as when you have an existing local git repo and you wish to link it to a new repository on github.
Within your code directory, add a remote repository, which we will call origin:
git remote add origin \<link to your repo\>
You can obtain the link to the repo from the green button marked “Clone or download” on your Github repository page. Be sure that is says “Clone with SSH”; if not, then first click the “Use SSH” button in the window. The link should look like
“<git@github.com>:\<your name\>/\<repository name\>.git”
How can I use git within my code editor?¶
RStudio:
Visual Studio Code
Background Resources:¶
On code sharing:¶
On licensing and Free/Open Source Software:¶
History of the Open Source Initiative. Website.
Morozov, E. 2013. The Meme Hustler. The Baffler.
Klabnik, S. 2019. The Culture War at the Heart of Open Source. Blog.
The case for Free use: reasons not to use a Creative Commons -NC license. FreedomDefined.org (wiki).
On version control:¶
GitHub’s quickstart guide - a walkthrough of setting up git, creating a repo
“Your first time with git and github” - an elaborated tutorial on setting up git on your local and connecting your git account to github using ssh keys for a streamlined process